
BY ANGELICA QUICKSEY
Although quantitative data and analysis can help us design better policies and programs, we have edged alarmingly close to a worldview that suggests the use of data automatically scrubs away ideology and prejudice. This worldview neglects the ways that numbers can reflect human biases and the ways data can be dangerous.
Data does not exist in a vacuum. It is collected, packaged, analyzed, shared, and reused. Prejudice or preferences can infect our data at any one of these stages. For example, ideology can play a role in what data is collected, as when officials in the Jim Crow south declined to collect accurate statistics on lynching. In that case, the true numbers had to be gathered independently by contemporary journalists and academics. More recently, Myanmar chose to exclude the Rohingya people from it’s 2014 census. In light of state violence against that group, this omission appears sinister; without an accurate count of the living, it is difficult to obtain an accurate count of the dead. These are extreme examples, but every dataset comes with its own baggage. To use data appropriately, we must understand how and why it came to be.
It takes a great deal of work to make data meaningful because the relationship between data and the real world is often messy. Math attempts to simplify this relationship and allows us to believe that x really does cause y. However, if we are not careful, our sophisticated statistical products – the complex regressions and opaque algorithms to which we increasingly yield our decisions – serve only to amplify human error.
Cathy O’Neil has written for years about the ways math had been used to make poor policy and management decisions. In one example, the value-added models being used to assess teacher performance across the U.S. often yielded inconsistent scores that were, statistically speaking, almost random. These models rely on standardized student tests and measure the difference between how well a student actually performed compared to their expected performance. As far back as 2004, researchers from the RAND corporation and Harvard Graduate School of Education suggested that relatively small class sizes (which make for small samples), poor testing data (which often is incomplete or missing values), and the many assumptions required to create value-added models make it difficult to precisely estimate the effect of a particular teacher, especially in relation to other teachers.
In another instance, predictive policing models that included “nuisance crimes” skewed their predictions toward areas that only appear crime-laden. Nuisance crimes are nonviolent crimes like stealing a candy bar or breaking a window and including these kinds of crimes in policing models creates, in O’Neil’s words, “a pernicious feedback loop.”The loop occurs because collecting data about nuisance crimes leads to more crime data, making certain neighborhoods look more criminal than they actually are. These, in turn, lead to more policing, which lead to still more data, and so on.
Last spring, four ProPublica investigators exposed racial bias in another mathematical model related to crime – in this case, the risk scores many counties use to determine the likelihood that a defendant will reoffend. ProPublica investigated the COMPAS algorithm, a proprietary algorithm produced by Northpointe, and one of several dozen risk assessment instruments used in the United States. These instruments use information about a defendant, such as previous crimes, education levels, or employment, to produce “a prediction based on a comparison of information about the individual to a similar data group.”However, many of the factors that make a defendant similar to another group are not predictive of criminal activity, and are often highly correlated with race and socioeconomic status. Further, the instruments have not been tested for validity (the term for the extent to which the analysis minimizes error) or were assessed by the same companies that produced them. These untested risk scores are often used by judges to set bail, and in some cases, decide sentencing. Which is to say, the risk score could be the deciding factor in whether a defendant goes to jail for six months or six years. In the case of COMPAS, Propublica found that the Broward County, Florida’s scores were likely to falsely flag black defendants as future criminals, while mislabeling white defendants as low risk. The algorithm was barely more accurate than a coin flip, yet generated systematic discrimination against black defendants. While objective measures of criminal activity could be invaluable to minimizing the impact of, say, biased judges, Broward County and others like it have merely replaced potentially-flawed humans with a definitively flawed formula.
Finally, decisions and policies based on good data and accurate analysis can still be unsound. Gerrymandering, for example, has become a data-driven exercise. When you look at the fourth congressional district in Chicago, the only conclusion you can draw is that public officials used socio-demographic data to create districts that would elect certain types of candidates. In short, motives matter.
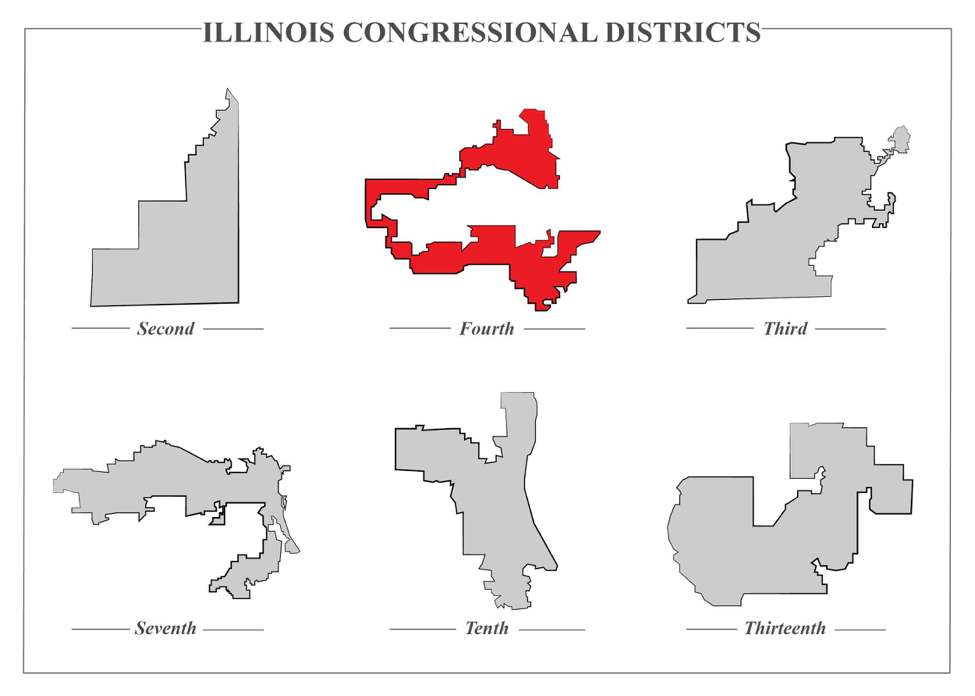
Illustration by Angelica Quicksey
This is not to say we should shun data altogether. I came to the Kennedy School, in part, to learn more rigorous tools for analysis and decision-making. The problem does not lie with numbers, statistics, formulas, or algorithms themselves. It lies in the assumption that data is always objective and thus unequivocally improves our decisions.
Data has always been power, and it has always been fraught. Moreover, with ever-expanding quantities of data, the growing use of it to make important decisions, and the speed at which information now moves, the potential for harm is much greater. Though we like to believe we can trust data more than people, a blind faith in numbers is no better than a blind faith in humans.
 Angelica Quicksey is a master of public policy student at John F. Kennedy School at Harvard University and a master of urban planning student at Harvard’s School of Design. She was a summer fellow in the Mayor’s Office of New Urban Mechanics.
Angelica Quicksey is a master of public policy student at John F. Kennedy School at Harvard University and a master of urban planning student at Harvard’s School of Design. She was a summer fellow in the Mayor’s Office of New Urban Mechanics.
Edited by Deepra Yusuf
Photo Credit: Lorenzo Cafaro via Pexels